Kaggle(캐글) - 주택 가격 예측 초보자 튜토리얼[Hellfer](2)
https://www.kaggle.com/code/jimmyyeung/house-regression-beginner-catboost-top-2/notebook
🔥House Regression: Beginner Catboost (Top 2%)🚀
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
위의 글을 보고 참고하여 작성하였습니다.
다음은 EDA(탐색적 데이터 분석)로 데이터 정보 확인, 결측치 확인, 기초 통계량 확인, 상관관계 히트맵에 대해 알아보겠습니다.
탐색적 데이터 분석(EDA)은 데이터를 시각화하고 요약하여 주요 특징을 이해하고, 패턴을 발견하여, 가설을 검증하는 과정입니다.
1. 기술 통계 : 데이터의 기본적인 통계 정보를 계산합니다.
- 평균, 중앙값, 최빈값, 분산, 표준편차 등을 구합니다.
2. 데이터 시각화 (Data Visualization): 히스토그램, 박스 플롯, 산점도, 꺾은선그래프 등이 있습니다.
3. 데이터 정제 (Data Cleaning) : 결측치, 이상치 등을 확인하고 처리합니다.
4. 상관 분석 (Correlation Analysis) : 변수들 간의 상관관계를 분석하여, 어떤 변수들이 서로 관련 있는지 파악합니다.
5. 가설 검정
데이터에 숨겨진 패턴이나 관계를 찾고, 향후 분석 방향을 설정하는 데 직관을 얻을 수 있습니다.
'train' 데이터프레임의 'SalePrice' 열 분포를 시각화합니다.
sns.distplot(train['SalePrice'], kde=True)

데이터 분포가 오른쪽 꼬리가 더 길고, 평균 > 중앙값 > 최빈값으로 양의 왜도(positive skewness)를 가지는 걸 알 수 있습니다.
따라서 오른쪽에 극단적으로 큰 값들이 존재합니다.
select_dtypes(include = ['number']를 사용하여 숫자형 열만 선택, corr() 메서드를 사용하여 상관계수 행렬을 계산합니다.
corr = train_test.select_dtypes(include=['number']).corr()
sns.heatmap(corr, cmap='viridis')

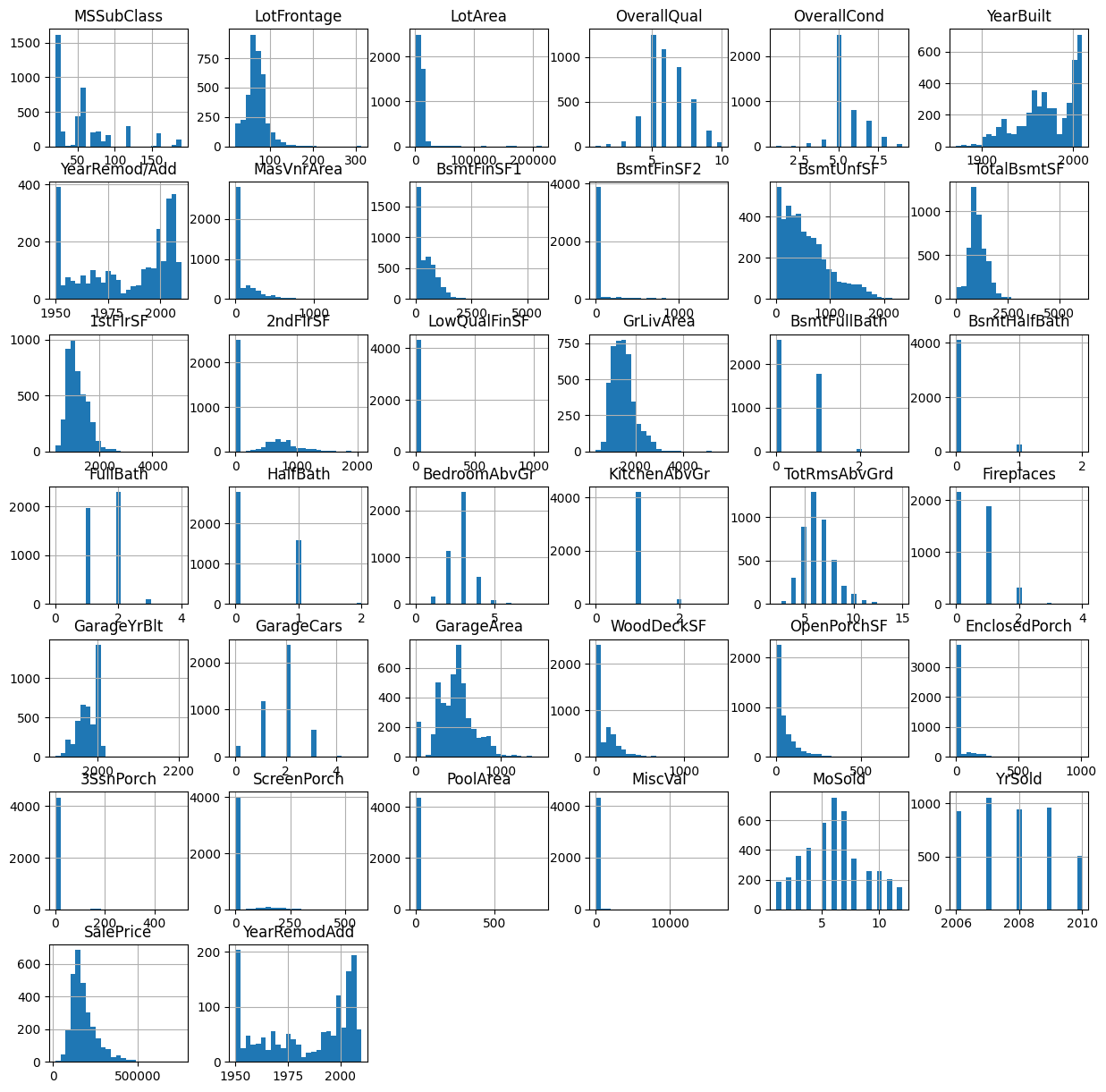
'numerical_features'에 포함된 숫자형 열들을 히스토그램으로 시각화합니다.
train_test[numerical_features].hist(bins=25, figsize=(15,15))
sns.pairplot을 사용하면 변수들 간의 관계를 한눈에 파악할 수 있으며, 상관관계가 높은 변수들을 쉽게 식별할 수 있습니다.
selected_features = ['SalePrice', 'OverallQual', 'GrLivArea', 'GarageCars', 'TotalBsmtSF', 'FullBath', 'YearBuilt']
sns.pairplot(data=train_test[selected_features], size=2)

'GrLivArea', 'SalePrice' 간의 관계를 산점도와 함께 선형 회귀선으로 시각화합니다.
sns.regplot(data=train_test, x='GrLivArea', y='SalePrice')

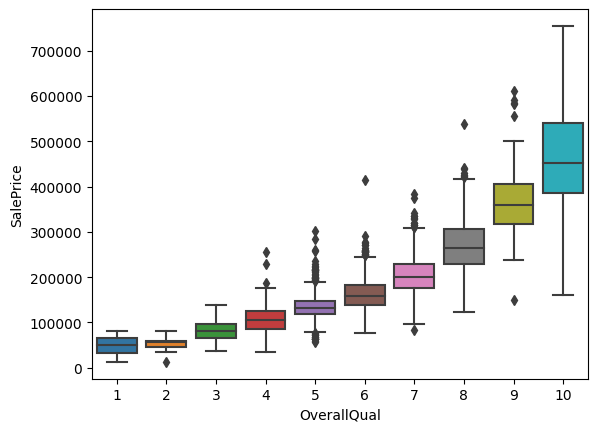
'OverallQual'(품질), 'SalePrice 간의 관계를 상자 그림으로 시각화합니다.
데이터 분포, 중앙값, 사분위 수, 이상치를 보여줍니다.
sns.boxplot(x='OverallQual', y='SalePrice', data=train_test)
'YearBuilt', 'SalePrice' 간의 관계를 상자 그림으로 시각화합니다.
sns.boxplot(x='YearBuilt', y='SalePrice', data=train_test)
